前言
延續上一篇 w4560000 - Prometheus 學習筆記-2
本篇透過建立 Alert Rule、AlertManager 以及發信告警來記錄學習
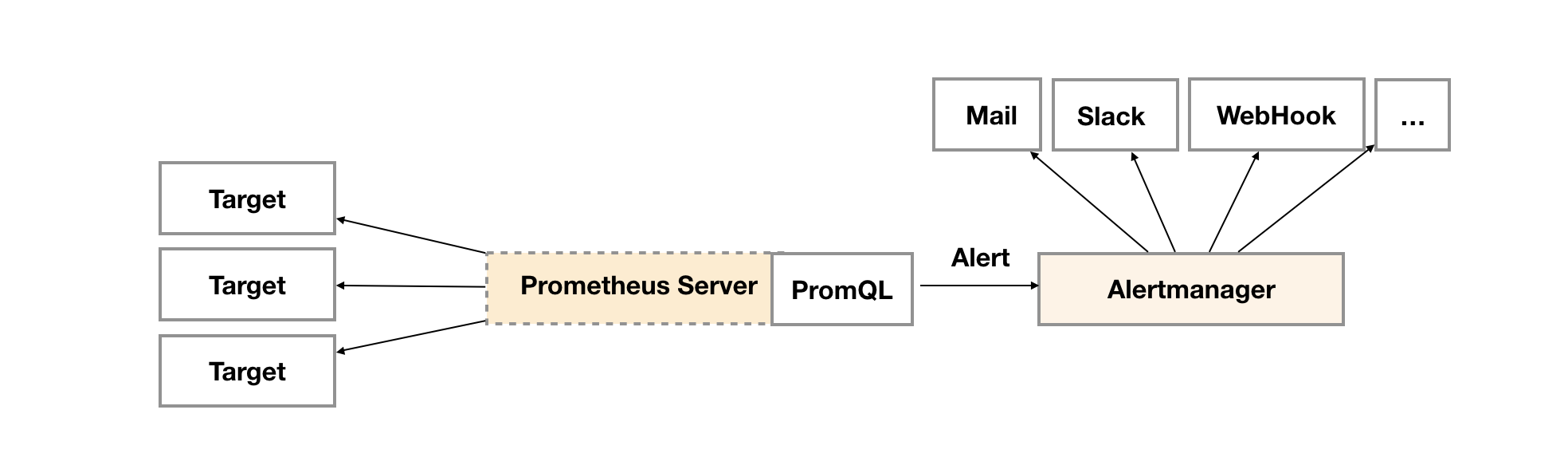
Prometheus Alert Rule 會在 Prometheus 設定
有三種狀態- Inactive: 沒有被觸發的狀態
- Pending: evaluation_interval 定期檢查時,檢查到有異常,但持續時間還沒有超過 rule 裡 for 的時間
- Firing: 異常持續時間 超過 rule 裡 for 的時間
當狀態達到 firing,則會通知 AlertManager,再由 AlertManager 接續告警流程
AlertManager 是 Prometheus 的一個組件,當 Prometheus 達到 Alert Rule Firing 狀態,則會通知 AlertManager 來進行告警
備註:
evaluation_interval= 執行 Rules 的時間間隔,為 Prometheus Server Global 設定值之一
作業環境
Windows 10 Professional (22H2)
Docker Desktop
Docker Compose
設定說明
可參考原始碼 Github - w4560000
Recording rules
Recording rules 是 Prometheus 中的一項功能
當查詢時的表達式運算成本較高或是執行時間較久時
可以建置 Recording rules 來預先算好資料,避免每次查詢都要重新運算
recording_rules.yml
groups:
- name: demo-recording
rules:
- record: demo_recording_net_rate_bps
expr: rate(net_bytes_recv[2m])*8
Alert Rule
alert_rules.yml
groups:
- name: example
rules:
- alert: net_input_rate_bps > 2000
expr: demo_recording_net_rate_bps > 2000
for: 2m
labels:
severity: warn
expr條件for持續超過 2 分鐘
rule 檢查時間是透過 evaluation_interval 在控制
Prometheus Global 設定
scrape_interval固定幾秒撈取 Metrics 一次,一般正常可設定 30 sevaluation_interval固定多久會檢查 rule 條件是否異常,一般正常可設定 40 s
一般來說evaluation_interval會比scrape_interval大一點
但不能大太多,若差距太多,則會檢查不到中間發生異常的狀況
alertManager.yml
route:
receiver: demo
receivers:
- name: demo
email_configs:
- to: leozheng0411@gmail.com
from: leozheng0411@gmail.com
smarthost: smtp.gmail.com:587
auth_username: leozheng0411@gmail.com
auth_identity: leozheng0411@gmail.com
auth_password: xxx
若是用 Gmail 的話,auth_password 填入應用程式密碼
可參考 w4560000 - .Net Core 3.1 設定 NLog 寄信流程 前半部取得應用程式密碼流程
docker-compose.yml
version: "3.0"
services:
telegraf:
image: telegraf:1.16.0
restart: always
container_name: telegraf
hostname: telegraf
ports:
- 9273:9273
volumes:
- ./telegraf/telegraf.conf:/etc/telegraf/telegraf.conf
- ./telegraf/telegraf.d/:/etc/telegraf/telegraf.d/
command: telegraf --config /etc/telegraf/telegraf.conf --config-directory /etc/telegraf/telegraf.d
prometheus:
image: prom/prometheus:latest
restart: always
container_name: prometheus
hostname: prometheus
ports:
- 9090:9090
volumes:
- ./prometheus:/etc/prometheus
command: --config.file=/etc/prometheus/prometheus.yml
alertmanager:
image: prom/alertmanager:latest
restart: always
container_name: alertmanager
hostname: alertmanager
ports:
- 9093:9093
volumes:
- ./alertmanager:/etc/alertmanager
command:
- --config.file=/etc/alertmanager/alertmanager.yml
host1:
image: busybox:latest
restart: unless-stopped
container_name: host1
hostname: host1
command: sh -c "while true; do sleep 3600; done"
操作流程
docker-compose up -d
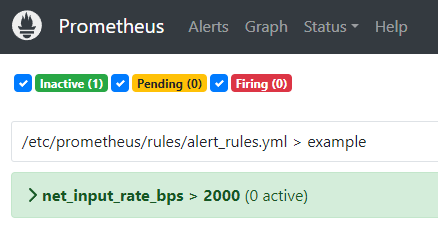
查看 Rules,確認 Rule 已建置
http://localhost:9090/rules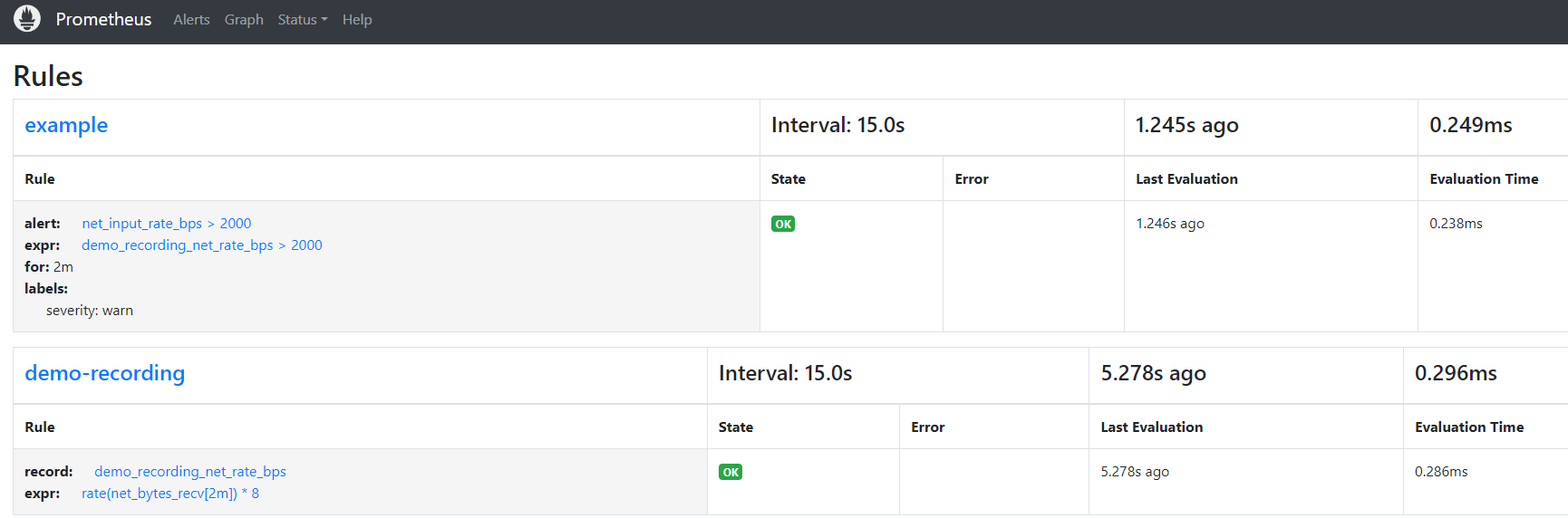
查詢 demo_recording_net_rate_bps (平均約1.3k左右)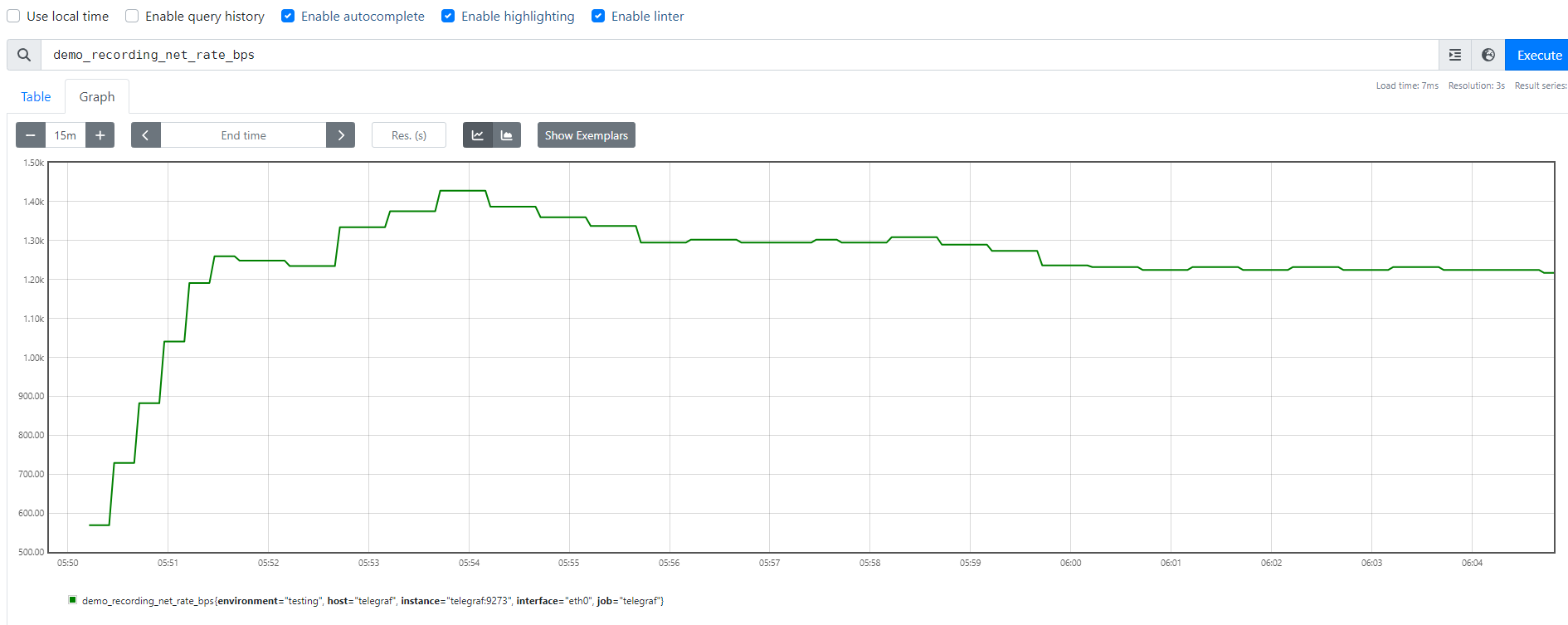
此時我們嘗試讓數值超過 2000,已達到告警值
docker exec -it host1 sh
ping telegraf -s 1024
# 輸出
PING telegraf (172.22.0.3): 1024 data bytes
1032 bytes from 172.22.0.3: seq=0 ttl=64 time=0.077 ms
1032 bytes from 172.22.0.3: seq=1 ttl=64 time=0.068 ms
1032 bytes from 172.22.0.3: seq=2 ttl=64 time=0.054 ms
1032 bytes from 172.22.0.3: seq=3 ttl=64 time=0.056 ms
1032 bytes from 172.22.0.3: seq=4 ttl=64 time=0.084 ms
... 略
一段時間後,已超過 2000 警戒值,狀態從 Inactive 變成 Pending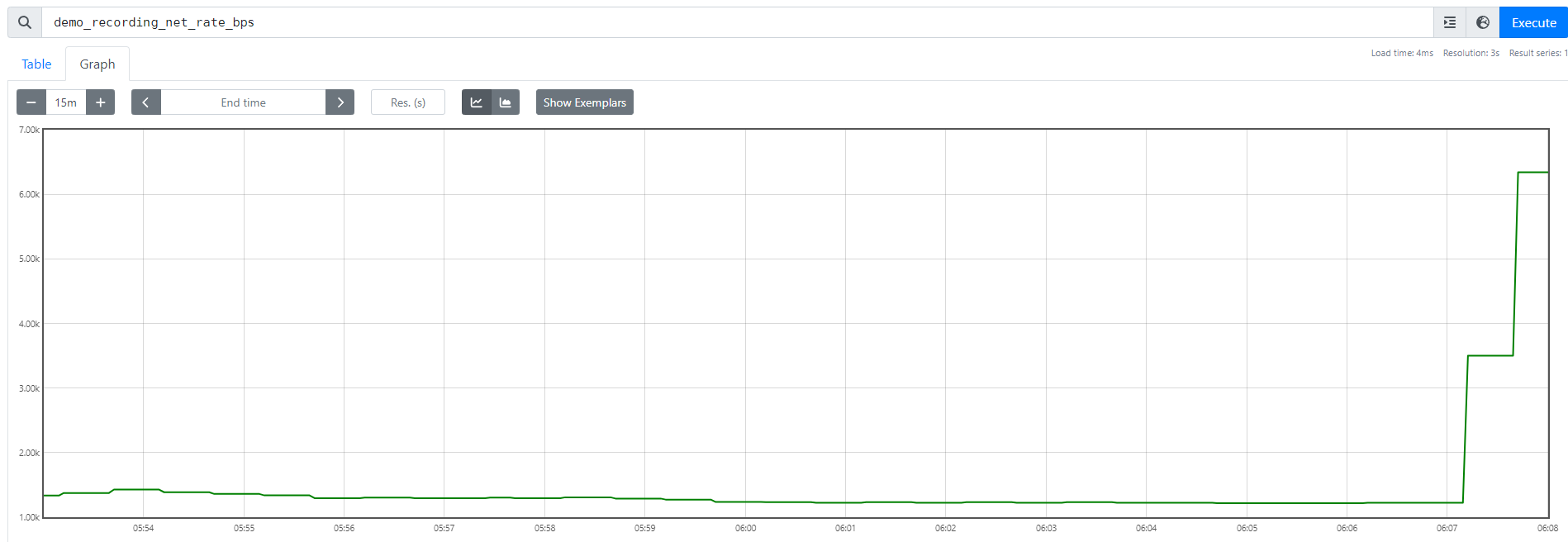
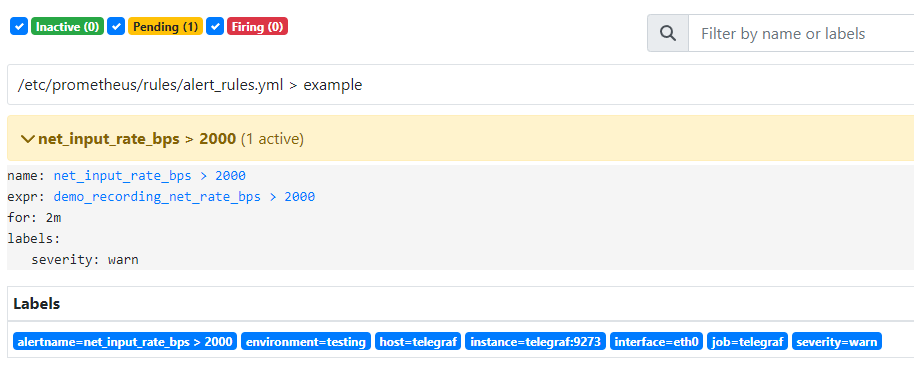
當異常時間持續 2 分鐘後,狀態從 Pending 變成 Firing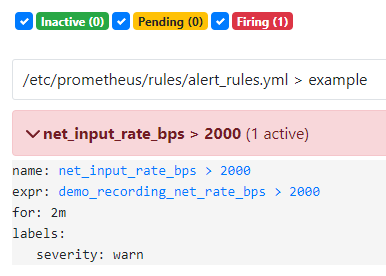
此時查看 AlertManager 可看到一筆 Alert 通知
http://localhost:9093/#/alerts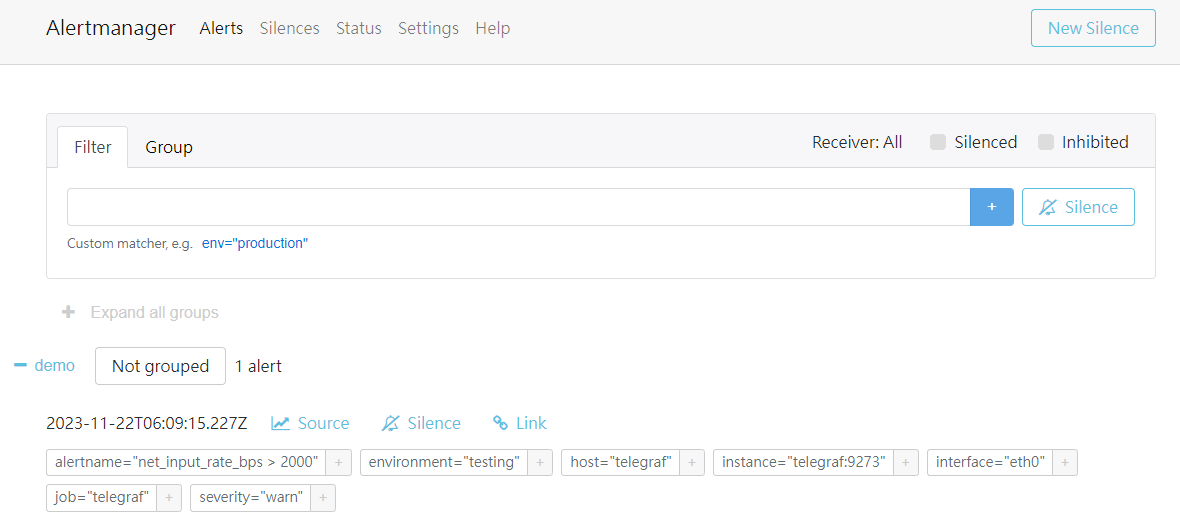
並且查看 Email 信箱,確認是否有收到告警通知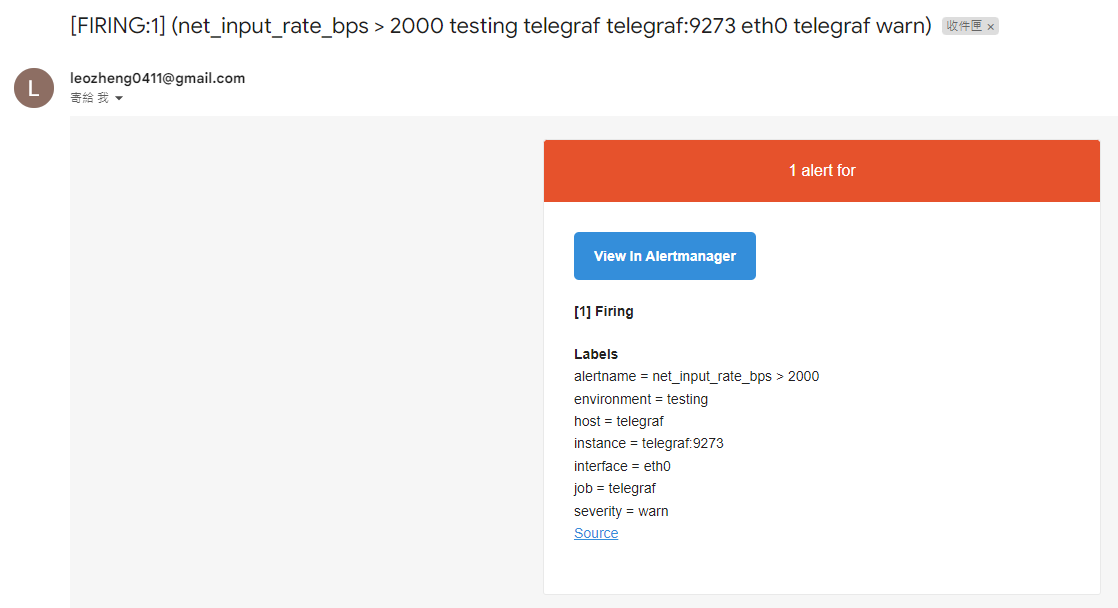
Alert Template
可添加 Lable、Annotation 來客製化告警內容
Prometheus - Template Examples
alert_rules.yml
添加告警說明
groups:
- name: example
rules:
- alert: net_input_rate_bps > 2000
expr: demo_recording_net_rate_bps > 2000
for: 2m
labels:
severity: warn
+ annotations:
+ description: 接收封包達到上限, net_input_rate_bps = {{ $value }}
再次執行測試
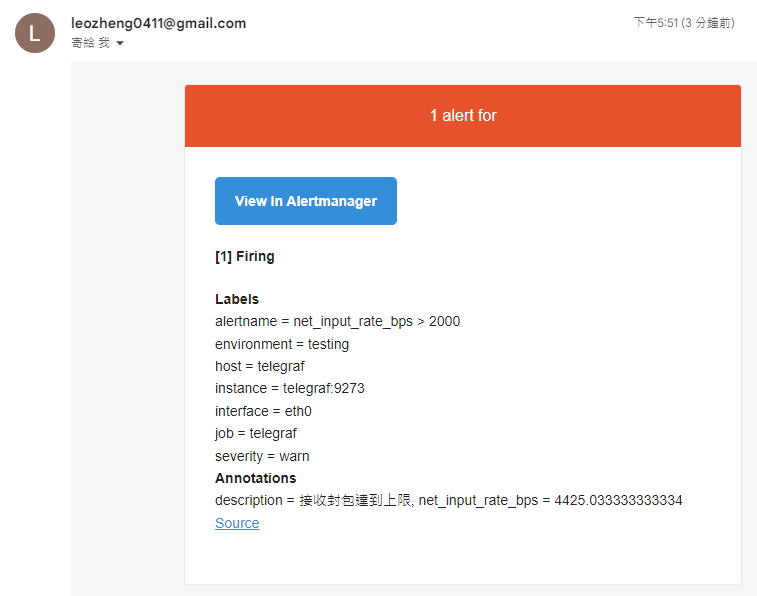
參考文件
Prometheus - Recording rules
Prometheus - email_config
轉載請註明來源,若有任何錯誤或表達不清楚的地方,歡迎在下方評論區留言,也可以來信至 leozheng0621@gmail.com
如果文章對您有幫助,歡迎斗內(donate),請我喝杯咖啡

